Akshit SinhaI am an incoming M.Phil student at the University of Cambridge in the Machine Learning and Machine Intelligence (MLMI) program. Read below to learn more about my research interests and past work. Before this, I graduated with a Bachelor's degree in Computer Science and Engineering with Honors from IIIT Hyderabad. As an undergraduate, I worked on machine learning with graphs under the supervision of Ponnurangam Kumaraguru at the amazing Precog lab. |

|
|
My current research focuses on understanding, evaluating and improving capabilities of AI systems (mainly large language models). My eventual goal is to help build AI that can reliably and autonomously perform complex tasks for extremely long periods of time, without human intervention.
|
|
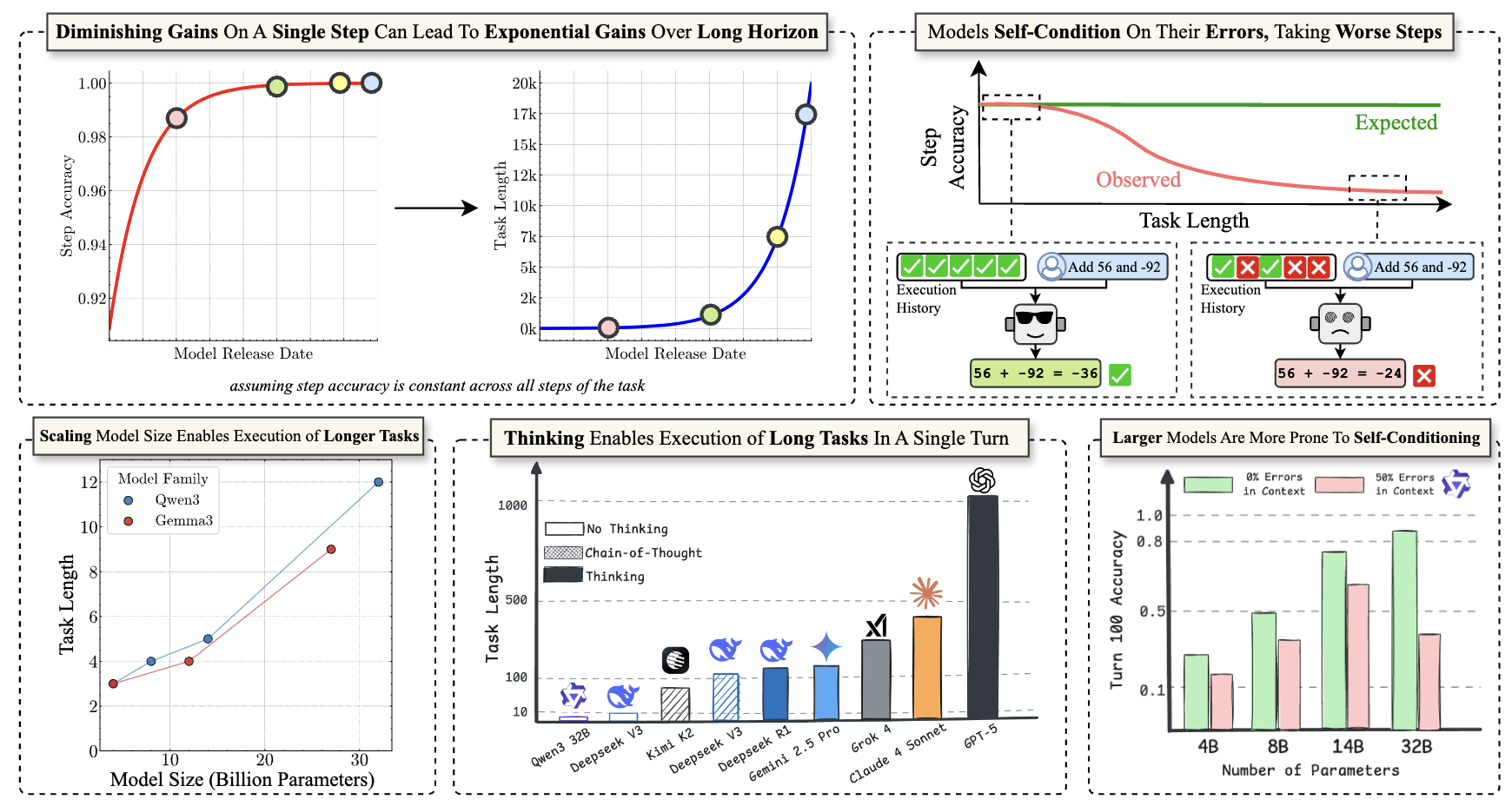
The Illusion of Diminishing Returns: Measuring Long Horizon Execution in LLMsAkshit Sinha*, Arvindh Arun*, Shashwat Goel*, Steffen Staab, Jonas Geiping Preprint, 2025 arxiv / code / We show several interesting results that challenge common assumptions about the capabilities of LLMs for long-horizon tasks. We find that (1) Scaling model size hugely improves long-horizon performance, (2) LLMs can effectively utilize intermediate steps to improve performance, and (3) LLMs struggle with what we call “self-conditioning”, where if they see more errors in their context, the make more errors in future steps. We find that intermediate reasoning steps can help mitigate this issue. Overall, our results suggest that LLMs have significant untapped potential for long-horizon tasks, and that with the right techniques, they can perform much better than previously thought. |
|
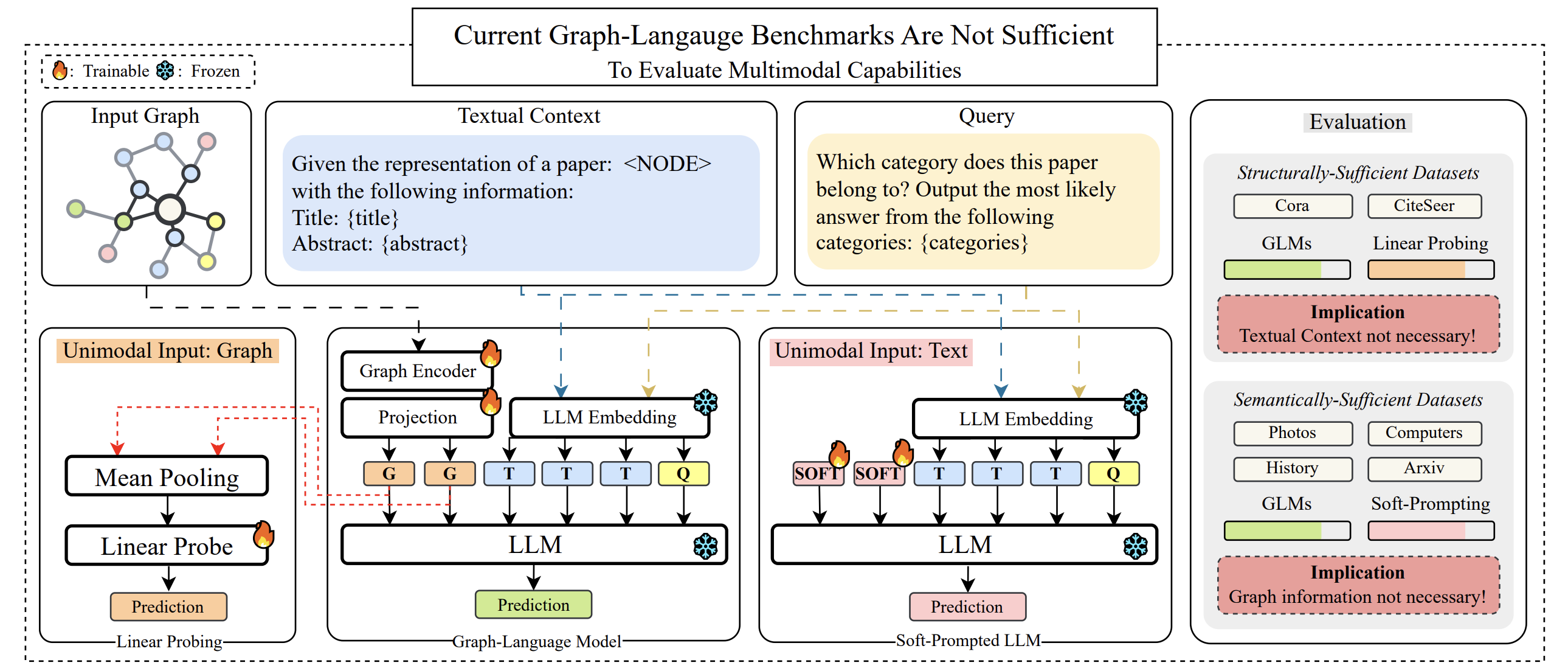
A Graph Talks, But Who's Listening? Rethinking Evaluations for Graph-Language ModelsSoham Petkar*, Hari Aakash K*, Anirudh Vempati, Akshit Sinha, Ponnurangam Kumarauguru, Chirag Agarwal Preprint, 2025 arxiv / code / We show that current evaluation methods for Graph-Language Models can be solved by using only one of the modalities (graph or text), indicating that these evaluations may not effectively measure the intended capabilities of these models. We propose a new evaluation framework that requires models to integrate both graph and text information to perform well, and find that current methods injecting graph information into language models do not outperform soft-prompted baselines on this new benchmark. |
|
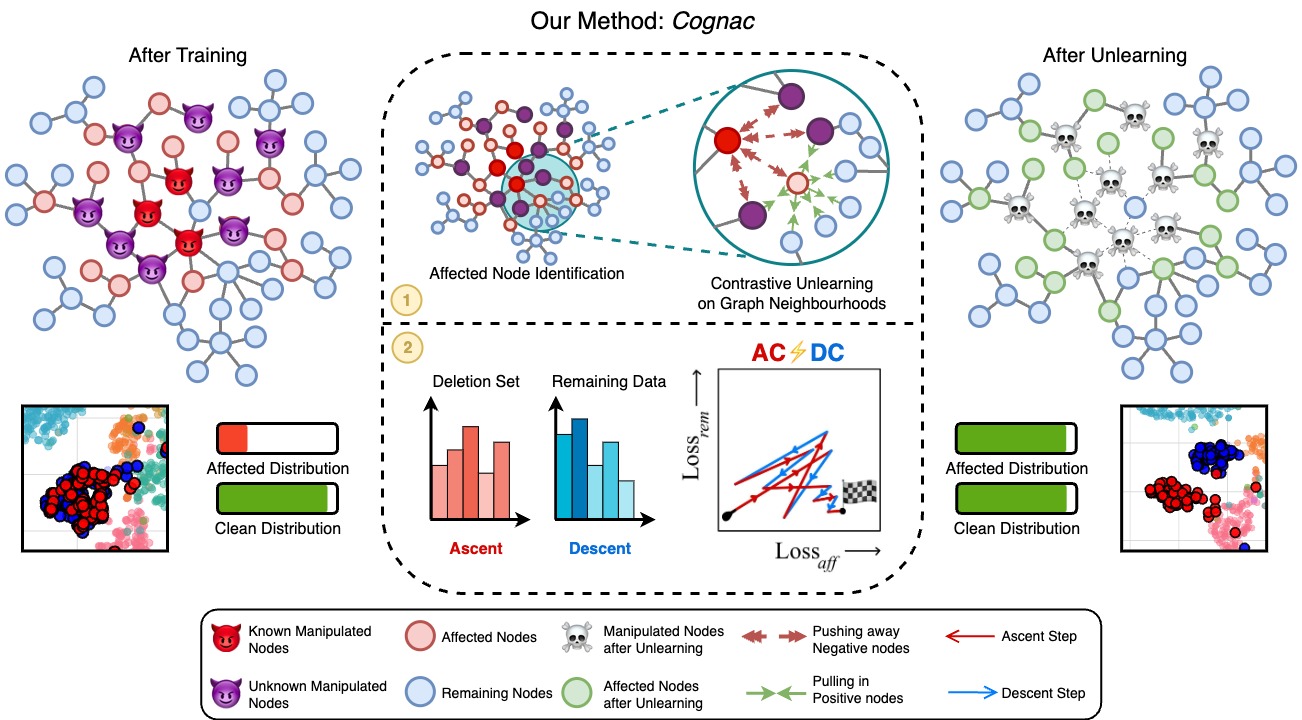
A Cognac Shot To Forget Bad Memories: Corrective Unlearning for GNNsVarshita Kolipaka*, Akshit Sinha*, Debangan Mishra, Sumit Kumar, Arvindh Arun, Shashwat Goel, Ponnurangam Kumaraguru 42nd International Conference on Machine Learning, 2025 arxiv / code / website / We introduce Cognac, a novel framework for corrective unlearning in Graph Neural Networks (GNNs). We show that existing state-of-the-art unlearning methods for GNNs are not effective in removing the influence of training data on model predictions. Cognac addresses this by leveraging a contrastive learning approach to learn a new representation of the graph that is less influenced by the data to be unlearned. |
Topo Goes Political: TDA-Based Controversy Detection in Imbalanced Reddit Political DataArvindh Arun, Karuna K Chandra, Akshit Sinha, Balakumar Velayutham, Jashn Arora, Manish Jain, Ponnurangam Kumaraguru BeyondFacts Workshop at ACM Web Conference, 2025 Best Paper Award arxiv / We present a novel approach to controversy detection in imbalanced Reddit political data using Topological Data Analysis (TDA). We release a new dataset focused on Indian political context and introduce topological features based on Persistent Homology that significantly improve performance on class-imbalanced controversy detection tasks. |
|
|
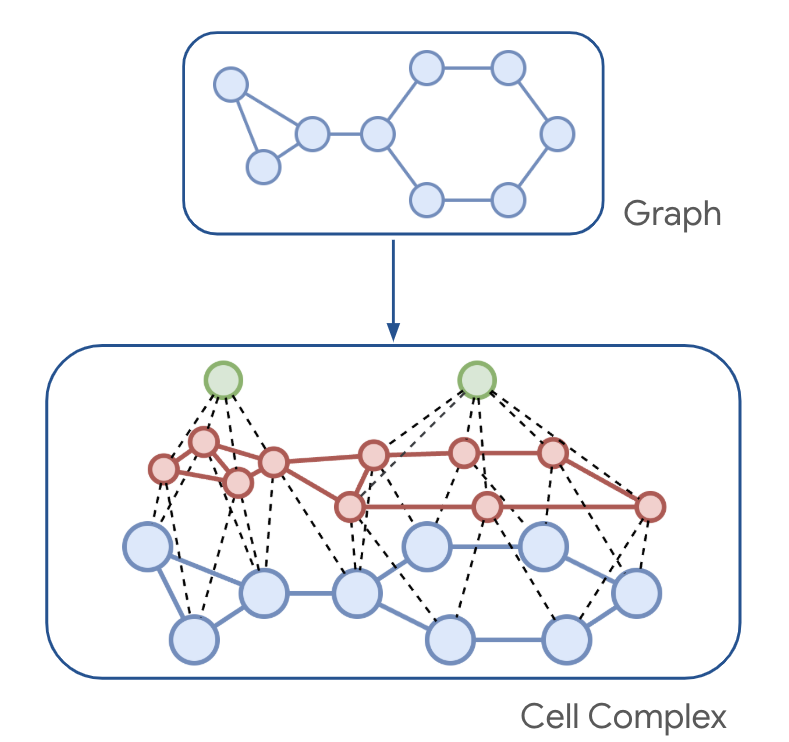
Higher Order Structures for Graph ExplanationsAkshit Sinha*, Sreeram Vennam*, Charu Sharma, Ponnurangam Kumaraguru 39th AAAI Conference on Artificial Intelligence, 2025 arxiv / code / We introduce Forge, a novel framework for generating explanations for Graph Neural Networks (GNNs) that leverages higher-order structures in graphs. Forge is designed to provide more comprehensive and interpretable explanations by considering relationships between groups of nodes rather than just pairwise interactions. |
Sanity Checks for Graph UnlearningVarshita Kolipaka*, Akshit Sinha*, Debangan Mishra, Sumit Kumar, Arvindh Arun, Shashwat Goel, Ponnurangam Kumaraguru 3rd Conference on Lifelong Learning Agents - Workshop Track, 2024 arxiv / We introduce a set of sanity checks for evaluating the effectiveness of unlearning methods in Graph Neural Networks (GNNs). |
|
Design and source code from Jon Barron's website |